jc has asked for the wisdom of the Perl Monks concerning the following question:
Hi,
I'm trying to research the internals of Perl's hash tables. Does anyone know how hash tables are implemented in Perl? Are these wrappers around some kind of C hash table implementation? Does anybody know where in the source tree I can find the files that implement Perl's hash tables?
Thanks if anyone can answer.
|
|---|
| Replies are listed 'Best First'. | |
|---|---|
|
Re: Perl's hash table implementation
by BrowserUk (Patriarch) on Oct 07, 2010 at 08:31 UTC | |
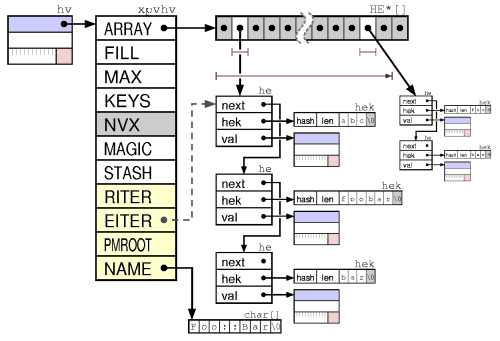
The clearest picture you'll see of how Perl's hashes are implemented is this one. For a little associated description, see PerlGuts Illustrated and scan down the section entitled "HV". If you have specific questions about the detail, I'd be willing to try to answer them. With the proviso that I'm just an "external observer" who happens to currently be writing an XS implementation of a hash-like mechanism, and am leaning heavily upon the perl hash code as a reference. I've basically become very familiar with it over the last 2 or 3 weeks. Examine what is said, not who speaks -- Silence betokens consent -- Love the truth but pardon error.
"Science is about questioning the status quo. Questioning authority".
In the absence of evidence, opinion is indistinguishable from prejudice.
| [reply] |
by Anonymous Monk on Oct 07, 2010 at 08:47 UTC | |
| [reply] |
by BrowserUk (Patriarch) on Oct 07, 2010 at 09:01 UTC | |
Oh! That's nice++ I especially like the "click to see others". Very cool.I've replaced my bookmark. Thank you so much for that. (The link, and the effort of updating the source if you are the one responsible.) Examine what is said, not who speaks -- Silence betokens consent -- Love the truth but pardon error.
"Science is about questioning the status quo. Questioning authority".
In the absence of evidence, opinion is indistinguishable from prejudice.
| [reply] |
by jc (Acolyte) on Oct 07, 2010 at 09:21 UTC | |
Great! Sounds like we have common interests then. Have you done any benchmarking experiments comparing hash table implementations? You know! Experiments with lots of unique additions. Experiments that involve lots of collisions (hash key already exists). Deletion operations. Conditional deletion operations etc. I'd be very interested in hearing your opinions. Can Perl's hash implementation be beat? Could it be optimised? What about on disk Hash tables using MLDBM? Could this be made to run any faster? How does it compare with using a database equivalent (e.g. MySQL)? | [reply] |
by BrowserUk (Patriarch) on Oct 07, 2010 at 11:31 UTC | |
Have you done any benchmarking experiments comparing hash table implementations? You know! Experiments with lots of unique additions. Experiments that involve lots of collisions (hash key already exists). Deletion operations. Conditional deletion operations etc. In general, any descent hash table implementation worthy of the name, is effectively (amortised) O(1) for all those operations. But of course, the devil is in the detail. As general purpose, anything you like as a key and anything you like as a payload, Perl's implementation is (probably) about as good as it gets. It main downside is that it's performance and generality comes at the cost of substantial memory usage. A worthwhile trade when speed and generality are the major criteria. Can Perl's hash implementation be beat? Could it be optimised? It absolutely depends upon the usage you are making of them; and for what criteria you are trying to optimise. My current effort have 3 aims: 1) to trade (a little) speed for significant memory reduction, by reducing the size of the internal structures used; 2) further reduce memory consumption by restricting keys to 255 characters thereby allowing me to get away with a single byte for key length; 3) avoid the need to use memory and cpu to sort the keys, by implementing the hash such that it supports in order traversal of the keys. All, whilst retaining the generality of key containing any byte values & supporting any SV as a payload. I'm currently bogged down in the typical (for me) XS memory & refcount management issues. What about on disk Hash tables using MLDBM? Could this be made to run any faster? How does it compare with using a database equivalent (e.g. MySQL)? I don't think performance was a high criteria for the implementation of MLDBM. I think they were aiming for a) basic CRUD behaviour (no referential constraints or normal form requirements); b) with nested hash-like ease of use (avoiding SQL complexities and bottlenecks); c) whilst retaining ACID reliability in a multi-user environment, with single-file simplicity. And I think they've got pretty close to those goals. To target speed would be to compromise their other goals. The bottom line is that it is nearly always possible to beat out an RDBMS for performance when you have specific knowledge of the data and usage requirements. But doing it requires custom effort for each specific set of requirements. RDBMSs (and Perl's hashes) are aimed at performing well across the widest possible range of general requirements. Examine what is said, not who speaks -- Silence betokens consent -- Love the truth but pardon error.
"Science is about questioning the status quo. Questioning authority".
In the absence of evidence, opinion is indistinguishable from prejudice.
| [reply] [d/l] |
by Anonymous Monk on Oct 07, 2010 at 21:26 UTC | |
| [reply] |
|
Re: Perl's hash table implementation
by Corion (Patriarch) on Oct 07, 2010 at 08:22 UTC | |
Hashes live in hv.h and hv.c. I'm not sure what you want to do and how much knowledge of the rest of Perl core is necessary to get there. Mostly, you'll be looking at macros using other macros in hv.h, but if you only aim at the implementation of Perl (memory) hashes, hv.c should be enough, and mostly "real" C code to boot. | [reply] [d/l] [select] |
by jc (Acolyte) on Oct 07, 2010 at 09:11 UTC | |
Hi, Basically, the kind of programming I do involves a lot of hash table work. This makes Perl an attractive technology for me because of its simple hash table interface. When doing an MSc in High Performance Computing I was not allowed to use Perl because my dissertation could not have been taken seriously because, and I quote from my supervisors, 'only C and Fortran are taken seriously as High performance programming languages'. So for my disssertation I had to use a less simple hash table C interface like http://www.cl.cam.ac.uk/~cwc22/hashtable/ And so, in a nutshell, I was just interested in comparing these Hash table implementations. Anyway, thanks for pointing me in the right direction. | [reply] |
by JavaFan (Canon) on Oct 07, 2010 at 09:33 UTC | |
This makes Perl an attractive technology for me because of its simple hash table interface.Yeah, but the implementation is focussed on Perl. It's certainly not a wrapper around an external C library. It won't be simple to lift the hash implementation out of perl, and adapt it for another language, and still have something that blends well with that language. only C and Fortran are taken seriously as High performance programming languagesThere may be a few others (or not...), but Perl certainly isn't known for being suitable as a "high performance" language when it comes to number crunching, or dealing with massive amounts of in-memory data. | [reply] |
by Anonymous Monk on Oct 07, 2010 at 12:20 UTC | |
| [reply] |
|
Re: Perl's hash table implementation
by halfcountplus (Hermit) on Oct 07, 2010 at 14:48 UTC | |
This is more about C and hash tables than perl. (I have not looked at the source, but the name "hash", would strongly imply that they are implemented using a hash table in C.) Maps from the C++ STL -- which are like perl hashes, and are very high performance --- are done using red black trees. Red black trees are based on Bayer trees with a limit of 2 keys per node and have a big O of log(n) for lookups. Fast databases commonly use Bayer trees for hash like operations. I've written a hash table in C for large data sets that performs comparably to the STL's "map" using Bayer trees with 4+ keys per node. The idea there is that you have a hash table of trees, and this works very well -- I am certainly not the only person to do it. So unless anyone knows more specifically exactly what kind of data structure is used in the perl source, keep in mind those three possibilities: | [reply] |
|
Re: Perl's hash table implementation
by locked_user sundialsvc4 (Abbot) on Oct 07, 2010 at 17:44 UTC | |
The “performance” of a hash-table will always depend very heavily upon the exact distribution of key-values presented. If the hash function is favorable to the actual key-data, distributing those values equitably among the buckets, performance of almost any table will be “good;” otherwise not. A lot depends also upon what you are measuring. Are you, say, looking for the time it takes to locate a particular key that (is|is not) there? The time required to do an insert or delete? The time required (and the algorithm) to resolve collisions? Memory can also be a factor. Hash tables often have a big footprint. Page faults can be a problem, rendering the hash-table worst case pretty close to “a disk file.” But... algorithms meant to assure good performance in the face of frequent paging-activity might be deemed to be “contributing to unnecessary overhead” if the tests were performed on a memory-plentiful system. The way that you frame your question has a great deal to do with what is the “right” answer. | |
by jc (Acolyte) on Oct 07, 2010 at 20:04 UTC | |
Hi, I'll make my questions a little bit clearer with some examples. The two main applications I have developed and experimented with were an n-gram counter and a high performance of the EM algorithm for automatically learning a translation probability table from bitexts. Let's consider counting n-gram occurrence in large document collections. If you are counting unigrams the vast majority of queries are collisions (the word has already been encountered and the count needs to be incremented). Performance problems are usually due to having to increase the number of buckets in the hash table due to an underestimation of how many buckets you would need. The longer the n-gram the less collisions, of course. The problem with collisions is that you have to wait for the result before you can make the decision to update the frequency. Now the EM implementation was built on HECToR, the largest super computer for academic purposes in Europe. HECToR has swap space disabled to keep applications memory bound. My implementation made careful memory usage counts to stop the hash table from growing too big. Again, due to the high cooccurrence of high frequency words in the bitexts in the training data the vast majority of queries were collisions. Again, the application was spending too much time waiting for the response to make the decision to update the most frequently occurring values in the table. Another interesting side effect of this was that any attempt to speed up my highly optimised version of this algorithm by using more processes in the shared memory space actually slowed it down. This was because serial optimisations based on cache usage go down the swanee when you start to use more cores. But this is by the by. In conclusion, I guess I'm more interested in seeing how different implementations compare in the case of a high collision rate. But, I'm also interested in general. I suppose a variety of benchmarks should be used. The only thing I'm not really interested in in is pageing issues. I have no interest in letting my hash tables overflow into swap space. In fact, exactly the opposite. | [reply] |
{kind=link}